

⭐️ 나중에 잊을 때쯤 다시 풀어볼 문제 ⭐️
초기 접근 방법
❗️처음에 생각한 방향
일단 문제를 해결할 알고리즘을 잘못 생각함
문제를 읽고, 결국 포함하고 있는 각 알파벳에 대한 빈도가 같으면 된다고 판단해서 코드를 구현
[ 처음 코드 ]
bool closeStrings(char * word1, char * word2){
int len1 = strlen(word1);
int len2 = strlen(word2);
int ht1[26]={0,}; // # of alphabets
int ht2[26]={0,};
for(int i=0; i<len1; i++){
ht1[word1[i]-97]++;
}
for(int i=0; i<len2; i++){
ht2[word2[i]-97]++;
}
for(int i=0; i<26; i++){
if(ht1[i] != ht2[i]) return false;
}
return true;
}
[ 두 번째 코드 ]
bool closeStrings(char * word1, char * word2){
int len1 = strlen(word1);
int len2 = strlen(word2);
int ht1[26]={0,}; // # of alphabets
int ht2[26]={0,};
int occur1[100001] = {0,};
int occur2[100001] = {0,};
for(int i=0; i<len1; i++){
ht1[word1[i]-97]++;
}
for(int i=0; i<len2; i++){
ht2[word2[i]-97]++;
}
for(int i=0; i<26; i++){
occur1[ht1[i]]++;
}
for(int i=0; i<26; i++){
occur2[ht2[i]]++;
}
for(int i=0; i<100001; i++){
if(occur1[i] != occur2[i]) return false;
}
return true;
}
최종 접근
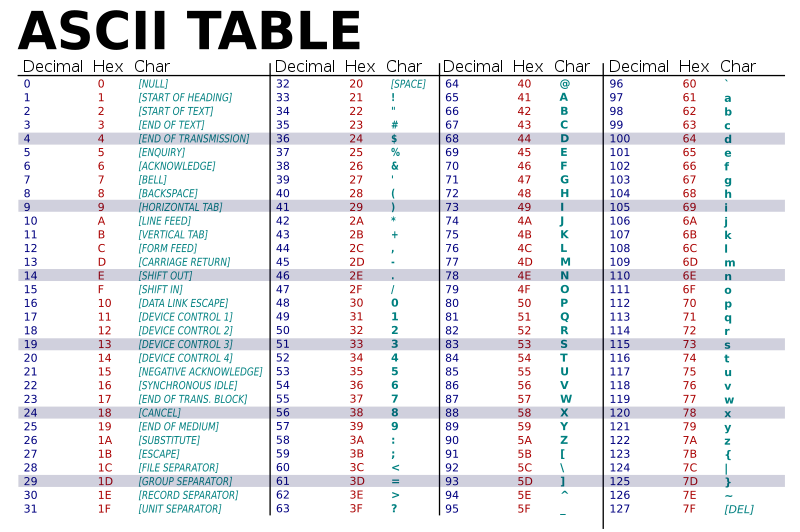
✅ character 하나씩 비교하는 것이기 때문에 아스키 코드를 참고
해시 테이블의 키값으로 넣기 편하게 구현하고자 ASCII를 사용했고
a의 아스키코드는 97이므로 KEY 값을 넣을 때 모두 -97을 해서 넣음
> 문제 조건에서 모든 알파벳은 소문자라고 했기 때문에 간단하게 구현 가능
✅ True 조건을 반환하기 위해서 파악한 문제해결규칙은
1. 사용된 알파벳이 모두 같아야함
2. 사용된 알파벳의 발생 빈도가 같아야함 (이 때, 순서는 중요하지 않고 같기만 하면 됨)
✅ 위에 1번 규칙에 대한 구현은 ht1[26]과 ht2[26]으로 파악가능
알파벳은 총 26자이므로 해시테이블의 크기는 26
먼저, 모든 char에 대해 해시테이블에 ++ 연산을 한 뒤, ht1과 ht2 비교를 통해 사용된 알파벳 비교
즉, ht1[i] != 0 && ht2[i] == 0 이면 사용된 알파벳이 다르다고 판단할 수 있음
✅ 2번 규칙인 발생빈도에 대한 고민을 많이 함
그냥 비교를 하자니, 반복문이 중첩되어 시간복잡도 부분에서 좋지않을 것으로 판단되었고,
또 해시테이블을 만들자니 이번 해시테이블의 크기는 100001이 되어야 함
그래도 해시테이블을 또 만드는 것이 낫다고 판단해서
occur1[100001]과 occur2[100001]를 두고 비교함
해시테이블에 대한 설명을 해보자면
만일 첫 단어에서 빈도 2가
1번 발생하면 occur1[2] = 1 이고,
2번 발생하면 2, 아니라면 0
즉, 이 테이블의 밸류값은 키값의 빈도가 몇 번 발생했냐임
구현
Runtime : 30ms
Beats 71.88% of users with C
int** findDifference(int* nums1, int nums1Size, int* nums2, int nums2Size, int* returnSize, int** returnColumnSizes){
*returnSize = 2;
*returnColumnSizes = (int*)malloc(2*sizeof(int));
int** ret = (int**)malloc((sizeof(int*) * 2));
ret[0] = (int*)malloc(nums1Size* sizeof(int));
ret[1] = (int*)malloc(nums2Size* sizeof(int));
int HT1[2001] = {0,};
int HT2[2001] = {0,};
for(int i=0; i<nums1Size; i++){
if(nums1[i]>=0) HT1[nums1[i]] = 1;
else HT1[nums1[i]+2001] = 1;
}
for(int i=0; i<nums2Size; i++){
if(nums2[i]>=0) HT2[nums2[i]] = 1;
else HT2[nums2[i]+2001] = 1;
}
int j=0;
for(int i=0; i<nums2Size; i++){
if(nums2[i]<0){
if(HT1[nums2[i]+2001] != 1){
ret[1][j++] = nums2[i];
HT1[nums2[i]+2001] = 1;
}
}
else{
if(HT1[nums2[i]] != 1){
ret[1][j++] = nums2[i];
HT1[nums2[i]] = 1;
}
}
}
(*returnColumnSizes)[1] = j;
j=0;
for(int i=0; i<nums1Size; i++){
if(nums1[i]<0){
if(HT2[nums1[i]+2001] != 1){
ret[0][j++] = nums1[i];
HT2[nums1[i]+2001] = 1;
}
}else{
if(HT2[nums1[i]] != 1){
ret[0][j++] = nums1[i];
HT2[nums1[i]] = 1;
}
}
}
(*returnColumnSizes)[0] = j;
return ret;
}
런타임 자체는 나쁘지 않게 나왔고, 메모리는 하위편에 속함
[ 고찰 ]
런타임을 줄이는 것이 더 좋을 지, 메모리 사용을 줄이는 것이 좋을지에 대해서 고민
내 코드와 메모리 사용량이 제일 적은 코드는 1MB 정도 차이가 나고,
내 코드와 런타임 사용량이 제일 많은 코드는 약 2.5배(55ms) 정도 차이가 남
하나만 선택할 수 있다면 어떤 것을 선택해서 코드를 구현해야할까..?
혹시나 이 질문에 대한 의견이 있으신 분들,,
댓글 부탁드립니다
저런 고민을 하다가
다른 사람들의 코드도 보며
메모리와 런타임을 모두 잡은 코드란 이런 것일까하고
참고하고자 가져옴!
int cmp (const void * a, const void * b) {
return ( *(int*)b - *(int*)a );
}
bool closeStrings(char * word1, char * word2){
size_t len = strlen(word1);
if (len != strlen(word2)) {
return false;
}
int i = 0;
int h1[26] = {0};
int h2[26] = {0};
for (i=0; i<len; i++) {
h1[word1[i]-'a']++;
h2[word2[i]-'a']++;
}
for (i=0; i<26; i++) {
if (h1[i]>0 && h2[i] == 0 || h2[i]>0 && h1[i] == 0) {
return false;
}
}
qsort(h1, 26, sizeof(int), cmp);
qsort(h2, 26, sizeof(int), cmp);
i=0;
while (i < 26 && h1[i] == h2[i]) {
i++;
}
return (i == 26);
}
[ 참고할 접근 ]
- Check if both words are of same length, if not return False
- Check if both words have same alphabets (by comparing set(word1) and set(word2)
- Make two lists having count of all alphabets one for word1 and one for word2, sort the lists, check if the lists are equal, if yes return True, else return False
Take aways
✅ 알파벳을 비교할 때는 아스키코드를 활용하자!
위의 내 코드와 같이 숫자 자체가 얼마인지 파악해서 계산해도 되지만
프로그래밍 언어는 사칙연산 시 자동으로 아스키코드로 변환해준다는 사실
즉, word[i] - 97 = word[i] - 'a' // 이 두 개는 같은 표현!
✅ 정렬되어 있지 않은 숫자 배열의 모든 숫자를 비교해야할 때 정렬 해보자!!!
>> C언어 qsort 사용하자!!!!!
'Algorithm > LeetCode' 카테고리의 다른 글
| LeetCode 735. Asteroid Collision (0) | 2023.08.17 |
|---|---|
| LeetCode 2390. Removing Stars From a String (0) | 2023.08.16 |
| LeetCode 1207. Unique Number of Occurrences (0) | 2023.08.16 |
| LeetCode 2215. Find the Difference of Two Arrays (0) | 2023.08.16 |
| LeetCode 1679. Max Number of K-Sum Pairs (0) | 2023.08.15 |